

Original article ISPreview UK:Read More
Connectivity to many popular internet services and systems across the world, such as Alexa, Snapchat, Fortnite, Signal, Perplexity, Slack, HMRC, Roblox, Ring and many more (payment providers, VoIP services etc.), are being disrupted this morning after cloud-platform Amazon Web Services (AWS) appeared to suffer a major global outage.
According to Ookla’s Downdetector service, the disruption appears to have started just after 7:44am, although in the past few minutes the situation has started to improve. AWS currently says that its engineers have applied “initial mitigations” and “are observing early signs of recovery” for at least some affected services.
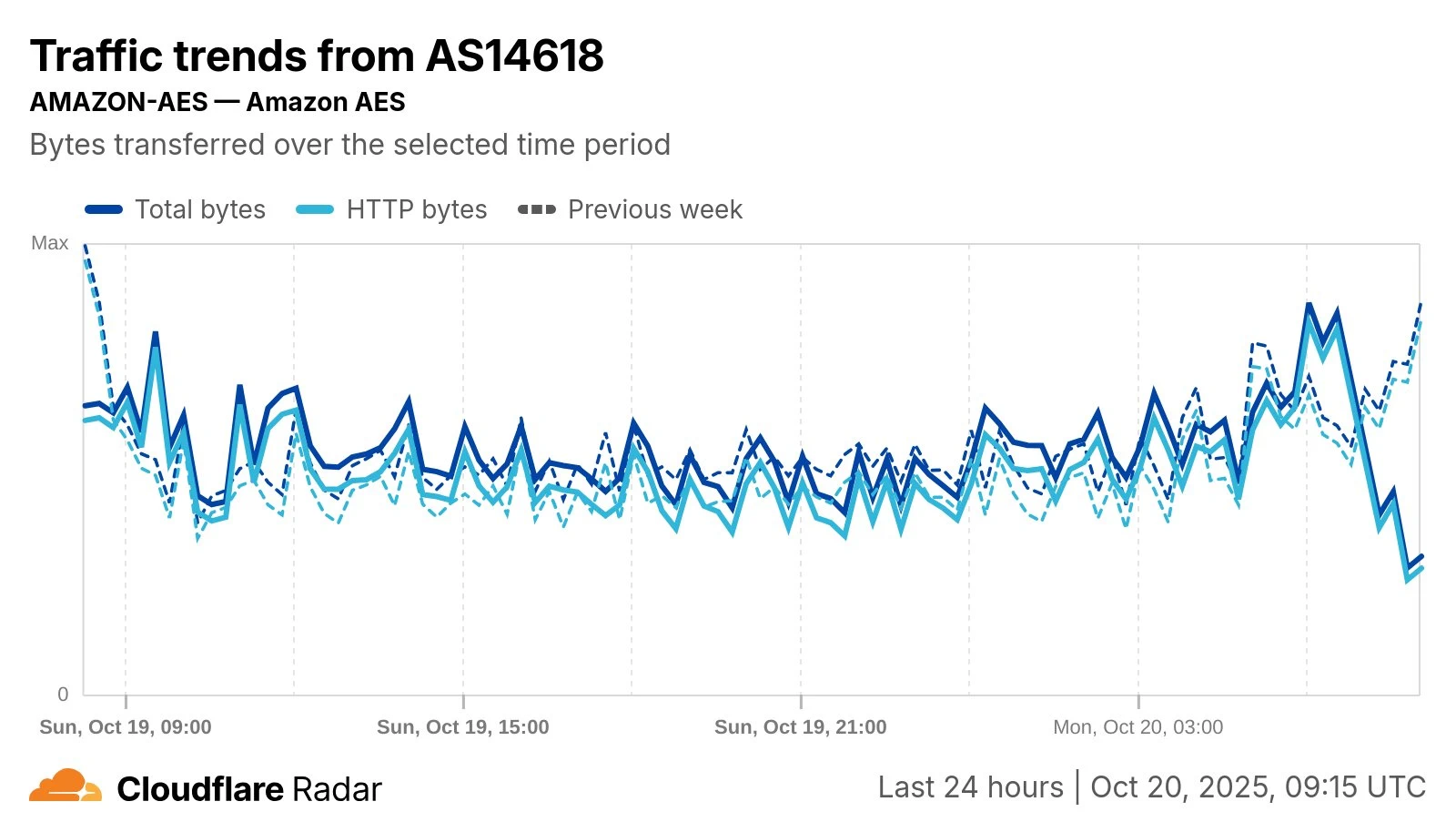
Meanwhile, Cloudflare’s data shows a clear drop in AS14618, associated with AWS’s US-East-1 region (Ashburn, Virginia) — one of AWS’s largest and busiest data centre regions — starting around 8am UK time. Traffic fell by as much as 68% at 9am UK time.
Some of the services impacted include Amazon itself (partial), Amazon Alexa, Amazon Music, Amazon Prime Video, Amazon Web Services, Ancestry, Asana, Atlassian, Bank of Scotland, Blink Security, BT, Canva, Clash Of Clans, Clash Royale, Coinbase, Dead By Daylight, Duolingo, EE, Epic Games Store, Eventbrite, Flickr, Fortnite, Halifax, Hay Day, HMRC, IMDB, Jira, Life360, Lloyds Bank, My Fitness Pal, Peloton, Perplexity AI, Playstation Network, Pokemon Go, Ring, Roblox, Rocket League, Signal, Sky, Slack, Smartsheet, Snapchat, Square, Tidal, Whatsapp, Wordle, Xero, Zoom and more.
UPDATE 10:46am
AWS are now reporting signs of recovery. “We are seeing significant signs of recovery. Most requests should now be succeeding. We continue to work through a backlog of queued requests. We will continue to provide additional information,” said the company.
Summary of AWS Service Status Updates
Increased Error Rates and LatenciesOct 20 2:27 AM PDT We are seeing significant signs of recovery. Most requests should now be succeeding. We continue to work through a backlog of queued requests. We will continue to provide additional information.Oct 20 2:22 AM PDT We have applied initial mitigations and we are observing early signs of recovery for some impacted AWS Services. During this time, requests may continue to fail as we work toward full resolution. We recommend customers retry failed requests. While requests begin succeeding, there may be additional latency and some services will have a backlog of work to work through, which may take additional time to fully process. We will continue to provide updates as we have more information to share, or by 3:15 AM.Oct 20 2:01 AM PDT We have identified a potential root cause for error rates for the DynamoDB APIs in the US-EAST-1 Region. Based on our investigation, the issue appears to be related to DNS resolution of the DynamoDB API endpoint in US-EAST-1. We are working on multiple parallel paths to accelerate recovery. This issue also affects other AWS Services in the US-EAST-1 Region. Global services or features that rely on US-EAST-1 endpoints such as IAM updates and DynamoDB Global tables may also be experiencing issues. During this time, customers may be unable to create or update Support Cases. We recommend customers continue to retry any failed requests. We will continue to provide updates as we have more information to share, or by 2:45 AM.Oct 20 1:26 AM PDT We can confirm significant error rates for requests made to the DynamoDB endpoint in the US-EAST-1 Region. This issue also affects other AWS Services in the US-EAST-1 Region as well. During this time, customers may be unable to create or update Support Cases. Engineers were immediately engaged and are actively working on both mitigating the issue, and fully understanding the root cause. We will continue to provide updates as we have more information to share, or by 2:00 AM.Oct 20 12:51 AM PDT We can confirm increased error rates and latencies for multiple AWS Services in the US-EAST-1 Region. This issue may also be affecting Case Creation through the AWS Support Center or the Support API. We are actively engaged and working to both mitigate the issue and understand root cause. We will provide an update in 45 minutes, or sooner if we have additional information to share.Oct 20 12:11 AM PDT We are investigating increased error rates and latencies for multiple AWS services in the US-EAST-1 Region. We will provide another update in the next 30-45 minutes.
UPDATE 11:34am
Despite AWS slowly getting back to normal, people are still reporting problems with various linked services, such as Ring. It may take time for everything to fully return. A number of broadband ISPs, such as YouFibre, appear to have support (phone, chat etc.) systems that depend upon AWS and have been disrupted. Sky Broadband are also reporting phone problems, although it’s unclear if they’re AWS related.